Hermes Agent
一个会自己学习、自己干活
的 AI 同事
3 个月吃下 OpenClaw 的流量,现在是 OpenRouter 全平台调用量第一
AGENDA
60 分钟,走完 8 条线。
Hermes 是什么
定义 · 团队 · 当前定位
vs OpenClaw + 选型
差异 · 优劣 · 怎么选
核心功能
六大能力 · 重点展开三个
能跑出什么效果
省时 · 省心 · 可复制
案例:单点优势 + 业务闭环
日报 · 竞品监控 · 内容运营
上手心得 + 30 天复利
5 条经验 · 真正回报在哪里
推荐 Skill
几个高频常用的工具
公司内申请流程
两种方式 · 零门槛上手
WHAT IS HERMES
一个装在消息软件里的 AI 同事
可以自己学习、自己长记性、自己定闹钟、自己跨平台干活的 AI 智能体。
会自我学习
完成一项任务后会自己沉淀成 SOP,越用越懂你的工作流
住在飞书里
15+ 消息平台,含飞书 / 企微 / 钉钉,群聊里 @ 它就能干活
完全开源
MIT License,免费可商用,社区每周都在迭代
WHERE IT STANDS NOW
它已经不是挑战者了 ——
它就是当下的第一名。
数据来源:OpenRouter App & Agent Rankings · 2026 年 5 月 21 日
OpenRouter 衡量的是真实付费调用量 —— 不是 GitHub 星数、不是营销口径。
全球真正在生产环境用的 Agent,已经从 OpenClaw 切到 Hermes。
HERMES VS OPENCLAW
一张表看清两者差距。
| 维度 | Hermes | OpenClaw |
|---|---|---|
| 谁做的 | Nous Research(专业模型实验室) | 个人开发者维护的社区项目 |
| 会不会自己学 | ✅ 干完一件事自动沉淀成"经验",下次直接复用 | ❌ 每次都要重新教,或者去社区找 Skill 装 |
| 记忆系统 | ✅ 三层结构 + 全文搜索,几周前的对话都查得到 | ⚠️ 靠几个文件硬记,长聊容易"失忆" |
| 能在哪用 | ✅ 飞书 / 企微 / 钉钉 / Telegram 等 15+ 平台 | ✅ 也支持飞书,但平台覆盖偏少 |
| 定时干活 | ✅ 一句人话:"每天 9 点给我做日报" | ⚠️ 配置偏简单,遇异常容易静默失败 |
| 多任务并行 | ✅ 一次派多个"分身 Agent" 同时干、自动汇总 | ⚠️ 基本只能排队 |
| 是否持续投入 | ✅ 模型实验室持续投入,更新很快 | ⚠️ 社区驱动,迭代相对慢 |
PROS & CONS
两边各自有什么优劣?
- 自己会学习、自己会进化 —— 越用越懂你
- 记忆系统强,跨会话、跨周、跨月都能找回上下文
- 多平台多任务同时跑,真把它当数字员工
- 模型实验室持续投入,迭代飞快
- Skill 社区量级还不如 OpenClaw(600–1200 vs 3000+)
- 中文教程、中文文档偏少(社区在快速补充)
- Skill 生态成熟,社区累计 3000+ 个插件可挑
- 老用户多,遇到问题查得到现成解决方案
- 不会自我学习,所有经验都要手动写或装
- 记忆能力一般,长聊容易丢上下文
- 多任务并行能力弱
- 迭代速度慢,社区流量正在下行
OpenClaw 是"你教它做事",Hermes 是"它自己学着做事"。
CHOOSE WISELY
3 个问题,帮你判断该选 Hermes 还是 OpenClaw。
| 问题 | 答这个 → Hermes | 答这个 → OpenClaw 就够 |
|---|---|---|
| Q1你打算用一次,还是用一个月以上? | 用一个月以上 | 用一次 / 偶尔用用 |
| Q2你愿不愿意"教它"几次(纠正、补充记忆)? | 愿意 · 我希望它越用越懂我 | 不愿意 · 我只想拿来就用 |
| Q3你的活更偏长期复利,还是短平快? | 长期复利 日报 / 监控 / 知识沉淀 |
短平快 写段代码 / 查个东西 |
CAPABILITY MAP
Hermes 的六大核心能力。
自我学习
自己写工作 SOP 并保存下来,同类活第 2 次几乎不用再教
长期记忆
自己的笔记本 + 员工档案,记得你的偏好、上次的方案、踩过的坑
多平台对话
住在飞书里,跟真同事一样,群聊里 @ 它就能干活
定时自动化
说一句话就能"定闹钟",到点自己开干
多 Agent 协作
派分身并行干活,同时调研多件事,最后汇总给你
人格定制
工作助手严谨、生活助手活泼,自由切换
高亮的 🧠 / 💾 / ⏰ 是今天要重点展开的三个能立刻感受到价值的能力。
CORE CAPABILITY · 1/3 · SELF-LEARNING
能力 1:自我学习(Skill 自沉淀)
怎么工作的
每当 Hermes 成功干完一件略复杂的活(比如"汇总客诉数据 → 排序 → 发群里"),它会自动把这套流程记下来,存成一份"工作 SOP"。
下次你只要说"再做一次客诉日报"——它就直接调出这份 SOP 跑完,几秒钟。
第一次让它配飞书机器人 webhook —— 花了 15 步 才跑通。↓
下次你说"帮我配一个飞书机器人给 XXX 项目" —— 它直接跑自己生成的 SOP,3 步搞定。
这件事的真正价值
说一句"再做一次"它就懂
个人工作流的复利效应
每个人教它一点,它变成集体经验
下次不会再犯同样的错
CORE CAPABILITY · 2/3 · MEMORY
能力 2:长期记忆
Hermes 内部有 3 套记忆系统 —— 不是一堆笔记文件,是分层结构。
📌 上周的方案能调出来
一句"上次那个客诉分类的方案",它直接搜出来
🧷 不用每次重新自我介绍
"我是做 CRM 的""周报发到 XX 群" —— 它自己记
🔄 跨设备记忆同步
上午电脑上聊一半,下午飞书继续,记忆完全连贯
CORE CAPABILITY · 3/3 · CRON
能力 3:定时自动化
跟它用人话说:"每周五下午 5 点给我整理本周项目进展,发到 XX 群" ——
它就自己定时了。
- ✕固定流程,遇异常就崩
- ✕只能跑写死的逻辑
- ✕失败靠人工查日志
- ✕改任务要改脚本、重新部署
- ✓调用 Agent 所有能力(搜、读、调接口、写文档、发飞书)
- ✓遇异常自己判断,能换思路
- ✓跑完会主动告诉你"今天有 XX 异常,要不要看下"
- ✓改任务跟它说一句话就改了
你不再是在调度"脚本" —— 而是在调度一个随时能处理异常的副手。
OUTCOMES
这些能力跑出来,
你能直接拿到三个产出。
省时
重复性工作 → 一句话触发
原来手工 30 分钟的事,现在 1 句话。
省心
工作记忆它替你存
跨周、跨月翻聊天记录的烦恼 没了。
可复制
个人工作流 → 全团队共享
你教会它一次,全组人都能复用。
背后只有一个原因:Agent 越用越懂你的工作流,复利效应。
CASE STUDY · STARTING POINT
先看几个 Hermes 明显更顺手的单点能力。
这些是日常工作中你能马上感受到差异的地方。
跨周跨月的上下文
几周前聊过的方案、记过的口径,一句话调回来,不用翻历史聊天
隐性规则会自动记住
你纠正它一次("这类客诉直接升 P1"),永久记住,下次不会再错
能搜回历史对话
上个月聊过的某个方案,一句"上次那个 XX"它自动搜出来,不用翻聊天记录
自带 40+ 内置工具
网页搜索、读写文件、调 API、操作浏览器… 开箱即用,不用一个个装插件
Skill 会自我精进
不只是自动生成,使用中发现哪里不对就自己改一次,跑得越久越精准
风格类工作
按你历史文章的口吻起草、按你惯用格式出报表,不用每次重新喂样本
把这些单点能力串起来 —— 就是接下来要讲的"闭环工作流"。
CASE 1 · 每日业务日报
案例 1:每日业务日报
打开 5+ 系统逐个筛选、导出昨天的数据
去重、拼接、按业务线分组、对齐前一日口径
翻数据找异常、算同比环比、判断哪些值得写进日报
套模板写解读、做趋势图
飞书群发、@ 重要人、跟进回复
通过飞书 Skill 读取多维表,跨多张表自动拼接
按你设定的"业务线/渠道"规则分组,自动对齐口径
找出 TOP 异常、算同比、超阈值自动标红 + 给原因分析
套你的模板,按你过去的语言风格写解读,自动生成趋势图
发到飞书群 + 自动 @ 负责人 + 超红线项邮件上报
CASE 1 · 第一次用 Hermes 跑业务日报 · 约 30 分钟
第一次怎么手把手教它
- 连接飞书 → 读取多维表「业务总览」昨日 234 条记录
- 按 A/B/C 聚合 → 算 4 项指标同比 → 识别 3 项超 ±10% 异常
- 调用图表工具 → 生成 7 日趋势图
- 套日报模板 → 写 4 段解读文字 → 询问"格式 OK 吗?"
⭐ 长期经验:「业务线 C 永远按 GMV 算」 → 以后所有涉及 C 的任务自动用这个口径
⭐ 沉淀为 Skill 「业务日报-v1」 → 明早 09:00 自动跑
CASE 1 · 教过一次之后 · 后续对话只需一句话
之后再用,它全记得
每次改动只需一句话 · 它会自动套用以前学过的规则
⭐ 我判断 D 跟 C 性质类似,自动套用了「按 GMV 算」的口径 —— 你校验一下对不对?
CASE 2 · 竞品监控
案例 2:竞品监控
一家家打开官网、翻应用市场评论、刷社交媒体
凭记忆跟上周比,手动记录"改了什么"
想"是冲我们来的吗""影响多大"
整理时间线、写风险提示、加建议
飞书群发 + 同步知识库 + 分别 @ 对应负责人
firecrawl 抓官网 + 应用市场评论 + 社交热度,一次到位
对比上周快照,精确列出"这周多了什么/变了什么"
判断竞品动作类型 + 关联历史模式 + 标注风险等级
时间线 + 影响分析 + 可借鉴点,一份 PDF
发群 + 存知识库 + 按角色分发(产品看功能,市场看营销)
CASE 2 · 第一次用 Hermes 跑竞品监控 · 约 30 分钟
第一次怎么手把手教它
- firecrawl 抓 3 家官网 → 获取产品页 / 价格页 / 帮助中心内容
- firecrawl 抓应用市场 → XX 47 条 / YY 23 条 / ZZ 91 条新评论
- firecrawl 抓微博 + 小红书 → 计算各家话题热度指数
- 对比分析 → 识别 2 项动作:XX 调低某产品价格 | ZZ 上线新保障
- 生成简报 → 时间线 + 风险评估 + 可借鉴点 → 询问确认
⭐ 长期经验:「差评集中在同一功能时单独标出」 → 以后所有竞品分析都用此规则
⭐ 沉淀为 Skill 「竞品周报-v1」 → 下周一自动跑
CASE 2 · 教过一次之后
之后再用,监控体系会自己长大
它不只记住怎么做 —— 它在跑的过程中会自动扩展自己的分类规则
⭐ 我已把「企业团险」加入竞品动作分类规则,以后所有竞品的这类动作都会自动监控。
需要你确认:这类动作的风险等级定为"中"还是"高"?
CASE 3 · 内容运营
案例 3:内容运营
翻热搜、看同行、想哪个能爆
想结构、找论据、调语气、改三遍
找图、调字号、排版进公众号
隔天手动去后台看阅读/点赞/留言
写总结、想下次改什么
firecrawl 抓热点 + 对照你历史爆款 + 给 5 个候选
按你历史文章的口吻和结构写初稿 + humanizer 去 AI 味
匹配风格配图 + 自动排版到飞书文档
24h 后自动抓表现数据,对比历史均值
分析为什么火/没火 → 结论写回经验,下次微调
CASE 3 · 第一次用 Hermes 跑内容运营 · 约 1 小时
第一次怎么手把手教它
- firecrawl 抓 4 个平台 → 获取本周保险科技热点 48 条
- 读取你的 3 篇参考文章 → 学你的语气、结构、用词偏好
- 对照历史爆款 → 筛出最可能起量的 5 个选题
- 按你的口吻试写第 1 篇 → humanizer 去 AI 味 → 生成终稿
⭐ 长期经验:"开头直接抛结论 / 用'大家'不用'用户'" → 以后所有文章都这样写
⭐ 沉淀为 Skill 「内容运营-v1」
CASE 3 · 教过一次之后
之后再用,越写越像你
它学的不只是格式 —— 是你的判断力 + 写作风格 + 什么话题能爆
🔍 分析:阅读高于均值 40%,可能因为标题用了"反直觉"结构 + 开头直接给数据。
⭐ 已将「反直觉标题 + 数据型开头」记入爆款规则 → 下次选题和写作时自动参考
TIPS · GETTING STARTED RIGHT
5 条上手心得 · 让 Hermes 真正动起来。
给它 10 分钟做"入职"
告诉它你的名字、岗位、主要负责什么、当前在做什么 —— 它会自动写进档案,之后每次都不用重新介绍。这 10 分钟回报最高。
头 2-3 周觉得"也没什么了不起"是正常的
Hermes 是复利型工具,第 1 周可能只是"还行",第 2-3 周才开始真懂你。试一次就放弃 = 完全错过它的核心价值。
先深做 1 件事,别一上来想包打天下
一上来让它干 10 件不同的活,结果哪件都不深、不稳。先挑 1 件重复性最高的活(比如客诉日报)练 1-2 周,跑稳了再加第 2 件。
纠正它一定要"明说"
"以后这种情况要 XX" + "请记到记忆里" —— 一句明确的纠正抵 10 次隐式信号。含糊地说"你这次写得不太对"它学不到东西。
头 2 周每周看一眼它的"记忆笔记"
让它把 MEMORY.md / USER.md 发给你看一眼,验证它对你的理解准不准、有没有过期信息。过期信息会让它越来越糊涂,让它清掉就行。
30-DAY COMPOUNDING CURVE
30 天复利曲线 —— 真正的回报在哪里?
头几天没感觉是正常的。真正的质变发生在第 14-30 天。
RECOMMENDED SKILLS
推荐几个高频常用的 Skill。
Skill ≈ "插件 / 专项 SOP"。下面这几个是网上口碑最好、跨岗位都用得到的。
| Skill | 能干什么 | 谁最受益 |
|---|---|---|
document-processing |
文档全家桶:PDF / Word / Excel / PPT 的真公式真排版,不是导出 CSV 那种凑合 | 几乎所有人 |
firecrawl |
给 Agent 用的网页抓取、搜索、浏览,反爬能力强,能稳定拿到结构化数据 | 调研 / 运营 / 竞品监控 |
mermaid-diagrams |
一段话生成流程图、时序图、架构图,做文档配图利器 | 产品 / 项目 / 运营 |
humanizer |
把"AI 味"的文案改成有观点、有语气的人话 | 内容 / 运营 / 市场 |
superpowers |
结构化多步工作流:构思 → 规划 → 执行 → 复盘,长任务最稳 | 任何要做"长任务"的人 |
document-processing + firecrawl —— 90% 的日常活儿就能跑了。用熟之后,它会自己从你的工作里长出新的 Skill。
HOW TO APPLY
公司内申请流程 —— 两种方式,二选一。
在「审批中心」自己发起
适合熟悉飞书审批的同事
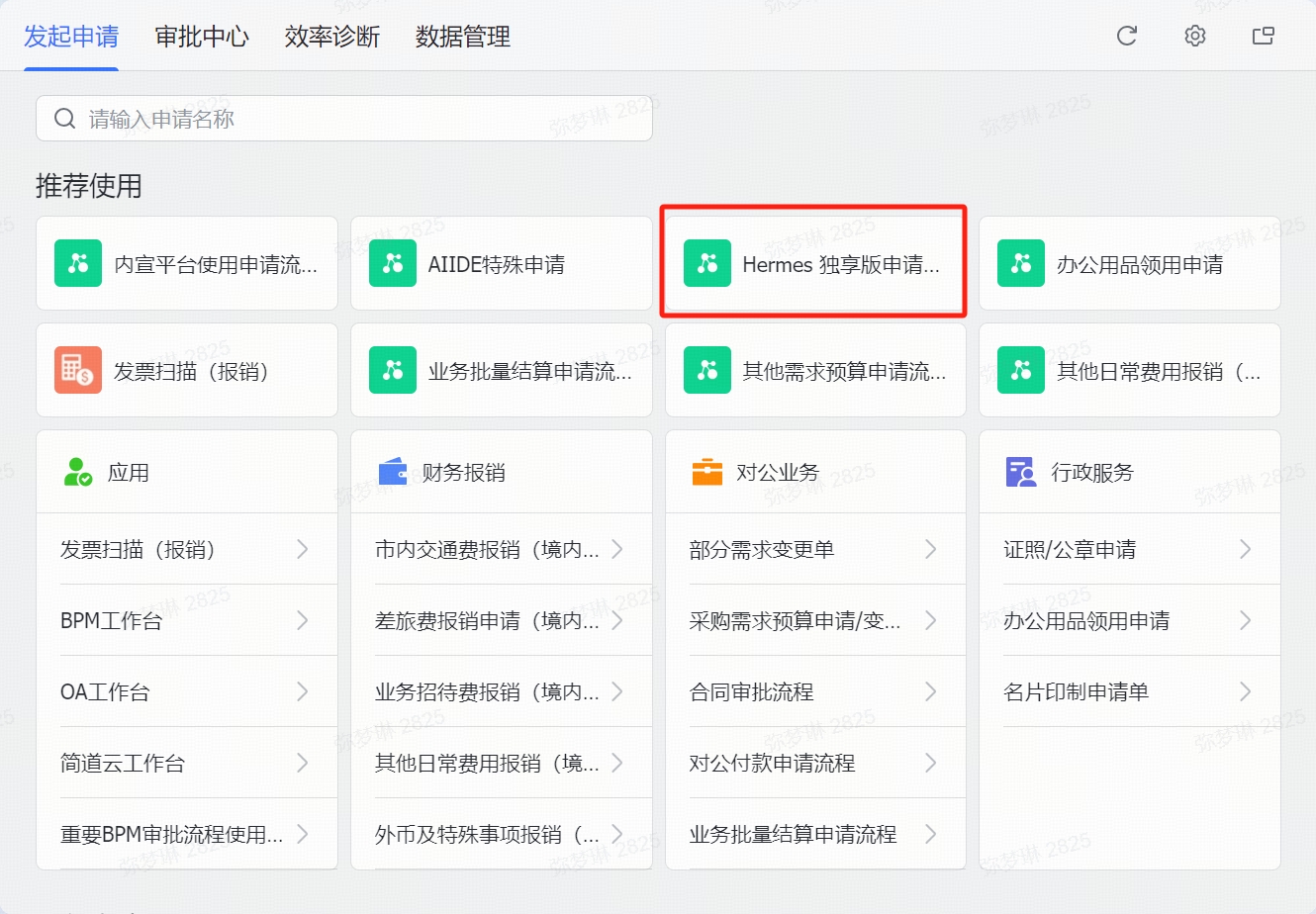
- 飞书 → 工作台 → 审批中心 → 发起申请
- 在「推荐使用」找到 「Hermes 独享版申请」
- 按页面提示填好信息,提交
- 等审批通过即可领用
找「流程龙虾」一聊就发起
全程对话式,不用研究表单字段
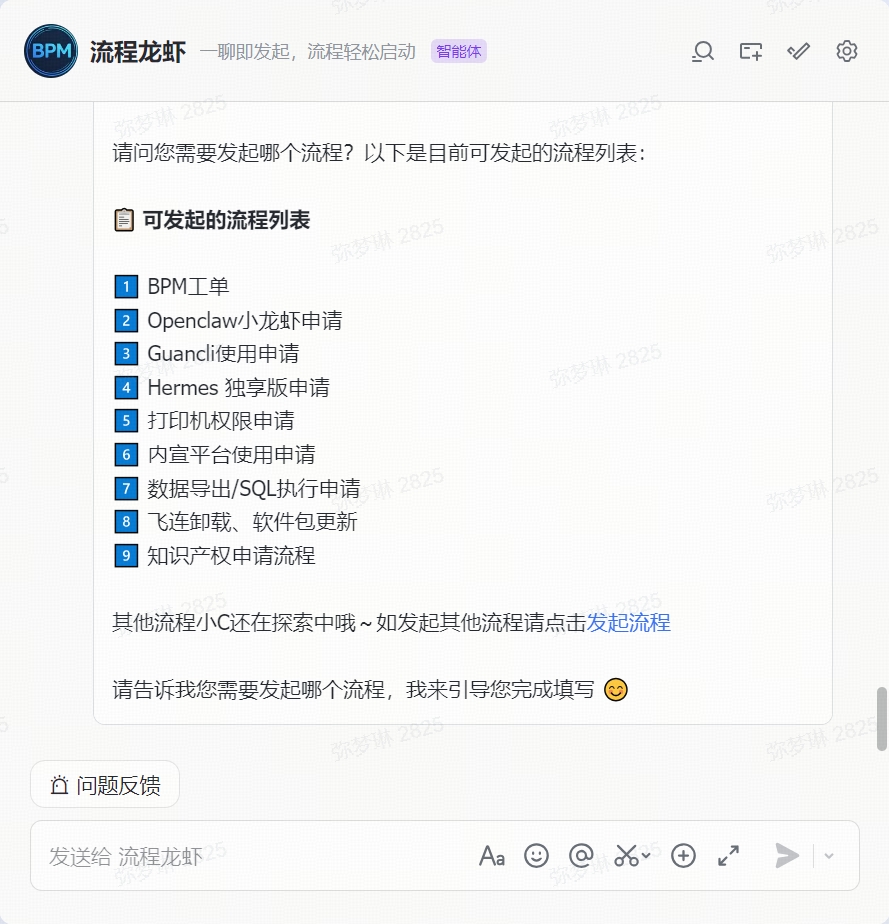
- 飞书搜索机器人 「流程龙虾」
- 对话框里说 "我要申请 Hermes 独享版"
- 龙虾会逐项引导你填完信息
- 提交,等审批通过即可领用
TAKEAWAYS & Q&A
三句话带走。
它不是聊天机器人,是一个会自我成长的"数字同事"。
Skill 自沉淀 + 三层记忆 + 跨平台 —— 把它当员工用,不是当工具用。
它真正的价值不是"帮你做一件事",而是"把一整条业务流跑完"。
日报、竞品监控、内容运营 —— 单点能力串成闭环,越跑越准。
公司内已经打通了申请通道,几乎零门槛上手。
审批中心 / 流程龙虾,二选一 —— 推荐每位同事都试一下。
SCAN TO JOIN
扫码继续了解 Hermes
用手机扫一扫 · 加入交流 · 获取最新动态